起因是收到一个任务:在PYNQ-Z2平台上搭建一个人脸识别系统。
当时第一时间就去了github,找到最热门的项目face_recognition,打算将其移植到arm平台上。然而在过程中遇到了数不胜数的坑。。其中之一就是依赖环境的配置。
dlib是一个提供机器学习和数据分析功能的C++库,也提供了python版本,使得可以通过python来调用其中的功能。然而,其提供方式简单粗暴,或许是为了能够达到每台机器的最佳性能,只提供了源码下载,自行编译安装的方法,甚至连Windows版的预编译包都没有提供(至少我没找到)。这就对于一些软件环境不全或者硬件配置不够的机器上安装该库的过程造成了一定的困难。(devs:反正我们的库是高级用途,那些辣鸡环境不配安装)
好在当前的硬件环境还是有通用型的,起码在同一平台下编译的软件可以在同一指令集架构Instruction Set Architecture, ISA下兼容运行,使得这些平台还是有运行dlib的可能。
本文即将提到的Pine A64+ 1GB SoC即属于上述的第二种情况:硬件配置不够。这里的不够指的并不是无法运行dlib。在编译过程中,目测到的最高内存占用达到2.1GB(amd64-aarch64交叉编译时),而默认配置的Pine A64内存1GB,内存交换空间swap 512MB,远远无法达到编译要求。实际上在Pine A64+上编译时,也可以观察到在内存不足时,会自动终止编译过程,并尝试从头开始。因而,在编译都无法完成的情况下,根本谈不上能不能运行。在对于交叉编译技术有了初步的了解后,决定使用amd64平台,配置更高的个人计算机进行交叉编译。
经过在Python包管理中心Python Package Index, PyPI的搜索后,发现一个名为crossenv的项目,根据描述,其目的在于为Python包交叉编译提供一个简化的配置过程,而这与我的目的恰好符合。过程记录如下。
第一步 下载目标平台的gcc工具链toolchain
到arm官网上可以找到下载地址(这里)。选择目标平台为aarch64-linux-gnu的工具链进行下载,使用时解压到linux文件系统中即可。
第二步 配置环境变量
甲 将工具链添加至搜索路径PATH
export PATH=/path/to/your/toolchain/bin
记得PATH中添加的是可执行文件的路径,所以不要忘记加上bin子目录。
/path/to/your/toolchain是工具链根目录的位置,例如/home/esper/gcc-arm-8.3-2019.03-x86_64-aarch64-linux-gnu
乙 配置编译相关的环境变量
Python库编译过程中会识别一些环境变量,比如CC, CFLAGS, C_INCLUDE_PATH一类的,C++对应的应该也是可用的。
export CC=aarch64-linux-gnu-gcc
export CXX=aarch64-linux-gnu-g++
这些是按照crossenv推荐而进行的设置。CFLAGS就不用设置了,可能会覆盖原有的比如-O2一类的优化参数。
第三步 安装crossenv(要求两个python版本一致)
甲 挂载目标平台的文件系统
由于需要为目标平台编译软件,故需要使用目标平台的配置信息进行编译时的配置。
假设使用的存储卡被系统分配的标识符为/dev/sdb,挂载至用户的家目录下:
mkdir pine64
sudo mount /dev/sdb2 ~/pine64
此时可通过~/pine64访问目标文件系统。
至于使用第二个分区的原因很简单,第一个是boot分区。
乙 配置目标平台的系统信息模块_sysconfigdata_m
备份原有_sysconfigdata.py,将_sysconfigdata_m.py复制为_sysconfigdata.py。Python原本的设计方法是由_sysconfigdata.py通过当前程序的变量决定加载的系统信息文件,而crossenv会检查两者之间的信息兼容性,还会报错(不知道原理是啥,反正这里让人摸不着头脑)
cd ~/pine64/usr/include/python3.5/
sudo mv _sysconfigdata.py _sysconfigdata.py.bak
sudo mv _sysconfigdata_m.py _sysconfigdata.py
丙 配置config-3.5m
crossenv不认带有后缀的config文件夹,使用软链接解决
sudo ln -s config-3.5m-* config-3.5m
丁 安装crossenv
pip3 install crossenv
python3 -m crossenv ~/pine64/usr/bin/python3 vcenv
使用以上命令安装crossenv,并根据目标平台的python可执行文件进行交叉编译环境的配置。
crossenv可以直接通过Python可执行文件进行调用,接收两个参数,其一为目标平台的Python可执行文件,其二为创建的虚拟环境的文件夹位置。以上命令将在当前目录生成一个名为vcenv的文件夹。
第四步 配置编译杂项
甲 配置python头文件
把对应架构下的pyconfig.h复制到gcc的include文件夹中
cp ~/pine64/usr/include/aarch64-linux-gnu/python3.5m/pyconfig.h /path/to/your/toolchain/aarch-linux-gnu/include/c++/8.3.0/aarch64-linux-gnu/python3.5m/pyconfig.h
目标文件夹为工具链中aarch-linux-gnu/include/c++/8.3.0/aarch64-linux-gnu/python3.5m子目录。理论上来说,只有最后一层文件夹python3.5m是缺失的,需要手动创建。
乙 修改strip
strip v. 脱掉;脱去(衣服)
使用该命令可以脱除生成的文件中多余的符号信息,缩小目标文件的大小,为cmake自动调用。然而不知为何,cmake咬死了只认/usr/bin/strip,导致其无法正确读取编译生成的文件,进而报错,阻碍了下一步工作的进行。
莫得办法,好在由于交叉编译不需要宿主机的工具链,使用取巧的办法,暂时屏蔽原有的strip,换成交叉编译所需要的。
备份原有strip,把交叉工具链的软链接一下,因为cmake不认识环境变量定义的strip。
sudo mv /usr/bin/strip /usr/bin/strip-host
sudo ln -s /path/to/toolchain/bin/aarch64-linux-gnu-strip /usr/bin/strip
完成编译后记得撤销操作
sudo rm /usr/bin/strip
sudo mv /ust/bin/strip-host /usr/bin/strip
第六步 编译打包
甲 编译
python setup.py build
乙 打包
python setup.py bdist_egg
轮子格式的参数为bdist_wheel
第七步 安装,完事
egg格式的可以使用easy_install命令直接安装。
whl格式的使用pip install命令安装。
不知为啥,我这里安装完以后又会自动重新开始下载编译dlib,取消就行了,再进Python发现已经可以import dlib了。
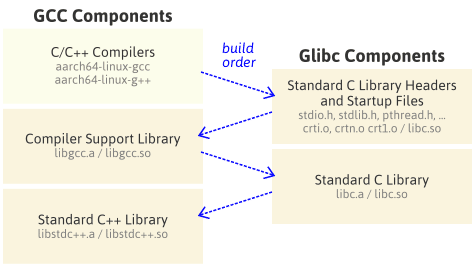
但是由于使用的工具链是gcc8,使用了glibc2.28的特性。而系统编译时只使用了2.23,故需要升级glibc方可测试所编译的dlib库是否可以正常运行。该过程将另起一篇文章叙述。
PYNQ-Z2的更麻烦,是32位系统。。。需要32位的python(咕咕)
=======================================================
后续补充
麻烦个吉尔,还简单些。采用的交叉工具链使用的glibc版本为2.28,而pine64所使用的glibc版本为2.23。然而这里兼容性恰好相反,pine64的系统只支持最高版本为2.23,而实际编译好的库需要使用2.27。glibc相当于系统的地基了,又不能轻易动。。。反倒是pynq还好,是近两年出来的,用的glibc库似乎恰好是2.27,编个32位的python,直接交叉编译,完成就能用。
也就是说,要在pine64上运行dlib的话,只有两个方法了:一个是拿更新的glibc(>=2.27)重新编译系统,另一个是编译一个更老的gcc(<=2.23)用于编译dlib。
=======================================================
我又回来了
可以利用虚拟内存完成编译
临时性地扩大总可用内存容量
dd if=/dev/zero of=/home/esper/tmp.swp bs=1024K count=1024
sudo chown root && sudo chgrp root && sudo chmod 600
sudo mkswap /home/esper/tmp/tmp.swp
sudo swapon /home/esper/tmp/tmp.swp
关机/重启会卸载虚拟内存,如何持久性地增大虚拟内存百度即可。