VS2019配置&踩坑
-
字体颜色配置

- 标准C头文件找不到的问题 根据这个页面描述,(应该是从vs2015起)标准C头文件就不再作为编译器的一部分,而是作为Windows SDK(即Windows软件开发套件)的一部分,因而,若是在安装VS时没有勾选任一版本的Windows SDK的话,会导致编译时报出找不到头文件的错误,这不是路径配置的问题!(供各位打算节省空间安装VS的读者参考)
字体颜色配置
可能是搜索关键词不对的原因吧。。弄了两天,换了个查法就找到解决方案了
仍然来自神奇的stackoverflow:https://stackoverflow.com/questions/42829675/visual-studio-2017-fails-to-install-offline-with-unable-to-download-installatio
在制作好的离线安装包目录下有一个certificates文件夹,把里面的证书全部安装至本地计算机,然后启动安装程序即可。
Ура!!!!!!
盯着procmon看了一上午,打算找出潜在的缓存文件或者注册表项,结果唯一发现的可疑点就是安装程序在注册表证书这一块做了不少操作,结果还真是缺少证书啊。。。
反正身边也没有电脑做实验了,win7虚拟机的.NET版本不够,懒得升级了,因而并没有做测试。
不过so大佬们的操作我还是十分相信的
原因:官网提供的预编译包使用的glibc版本为2.28,而16年编译的Pine A64系统上使用的还是glibc2.23。由于缺乏高版本的符号支持,使用新版本的编译器编译的程序可能会出现找不到符号一类的问题。(在重新编译系统和编译器之间,我选择了后者,因为实在不知道该如何配置多环境glibc了。。)
参考:https://preshing.com/20141119/how-to-build-a-gcc-cross-compiler/
基本上就是翻译了
>>> 本文中的所有操作都假设在用户的家目录下的gnu-aarch64文件夹~/gnu-aarch64/下执行 <<<
>>> 用于编译的文件夹以build-作为前缀,如build-gcc <<<
>>> 编译完成后的工具链安装在dist目录下 <<<
系统为Ubuntu 16.04 Server
这里使用/home/esper/作为用户的家目录。
一套完整的编译工具链由三个部分组成,binutils,gcc,glibc。
三者的功能分别如下:
binutils:顾名思义,与二进制binary相关,负责对二进制文件相关的操作,比如常见的ld(可能全称是link dynamics),即链接动态库,此时的文件已经是编译为二进制的对象文件object file了;在之前的曾经提到过的strip,删除二进制文件中不必要的符号信息,等等。
gcc:全称GNU Compiler Collection,是GNU开源计划的编译器套件。完成的功能是将高级语言转化为对应的机器代码/二进制文件。stdc++库是和gcc一同发布的 -> 想要降级libstdc++,就要降级gcc。
glibc:glibc是GNU发布的libc库,即c运行库。glibc是linux系统中最底层的应用程序编程接口Application Programming Interface, API,几乎其它任何运行库都会依赖于glibc。(摘自百度百科)
事先说明:
error: cannot compute suffix of object files问题的话,说明你可能是提前开始了gcc的编译,或者没有配置好必要的环境变量。这一步包括所有相关的软件及其相关配置等。
通过包管理器安装-辅助软件包:texinfo, gettext, bison, 用于编译的gcc, make
源码-主要软件包:目标版本的gcc, binutils, glibc, 目标系统对应版本的linux内核源码
源码-辅助软件包:gmp, isl, mpc, mpfr, libiconv
其中软件的版本可通过包内的INSTALL文件中对软件包的要求进行确定。
其中不同发行网站(比如gnu官方和arm官方)提供的gcc源码包内,有的直接提供了可用版本的辅助软件包,有的可以通过contrib目录下的download_prerequisites脚本进行下载。
需要确保编译完的输出文件夹的bin目录在搜索路径search path中。
export PATH=/home/esper/gnu-aarch64/dist/bin:$PATH因为交叉工具链的编译是一个可以称为自举的过程,即先编译一部分,然后这一部分参与编译另一部分,直至编译完成。从文首的引用中借图可以清晰展示如下:
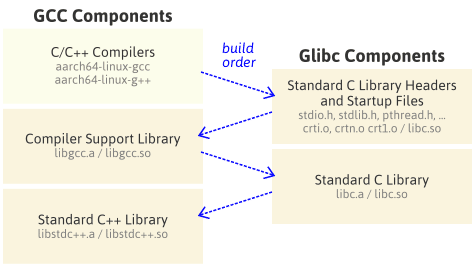
gcc和glibc都是交叉工具链的一部分,作为一个整体的工具链,像一个人走路一样左脚、右脚地迈进,而不是各自独立完成编译然后组合在一起。因而,在过程步骤上有点复杂。
binutils为了编译安装软件,对于二进制文件的操作是必不可少的。因而,要先编译用于目标平台的binutils以使得接下来可以修改能在目标平台上运行的程序。
tar xf binutils-2.26.1.tar.gz
mkdir build-binutils
cd build-binutils
../binutils-2.26.1/configure --prefix=/home/esper/gnu-aarch64/dist --target=aarch64-linux-gnu --disable-multilib
make -j4
make install
cd ..由于configure命令不允许使用相对路径,故需要使用绝对路径。将其替换为自己的用户名。
完成后,直接在命令行输入aarch64,然后多按几次tab键,应该会出现诸如aarch64-linux-gnu-ld的命令补全提示。
如果现象与上述一致,则该步骤成功完成。
参考我的这篇博客以获得pine64对应的内核源码。
但是由于在这里,我们的内核头文件不是为系统配置使用的,因而无需使用文中提到的来自longsleep大神的安装脚本。
tar xf linux-pine64-3.10.104-2-pine64.tar.gz
cd linux-pine64-3.10.104-2-pine64
make ARCH=arm64 INSTALL_HDR_PATH=/home/esper/gnu-aarch64/dist/aarch64-linux-gnu headers_install
cd ..将头文件安装到以架构命名的子文件夹中。这样做的好处是允许系统中同时配置有多个不同环境的编译套件,而且似乎gcc也贯彻落实了这一点——如果不这么做的话,往往会出现意料之外的错误。
gcc套件只是工具链的一部分,获得的gcc源码包中还含有libstdc++一类同捆发行的依赖库,在此时并不能完成编译。
可以将gmp, isl, mpc, mpfr, libiconv的源码文件夹链接或是直接解压到gcc源码目录下,configure命令若是识别到了不带版本后缀的文件夹名的话,会试图将该源码包编译,并用于后续的编译过程。否则需要在系统路径提供安装好的、满足版本要求的对应软件包。
tar xf gcc-arm-src-snapshot-8.3-2019.03.tar.xz
mkdir build-gcc
cd build-gcc
../gcc-arm-src-snapshot-8.3-2019.03/configure --target=aarch64-linux-gnu --prefix=/home/esper/gnu-aarch64/dist --with-bugurl=https://bugs.linaro.org/ --enable-gnu-indirect-function --enable-shared --disable-libssp --disable-libmudflap --enable-checking=release --enable-languages=c,c++,fortran --enable-fix-cortex-a53-843419 --disable-multilib
make -j4 all-gcc
make install-gcc
cd ..如果需要提供ada支持的话,需要安装flex包。由于我的后续工作中用不到,且为了节约时间,就没有编译部分语言的支持。
如果对于configure的参数有疑问的话,可以通过gcc -v获得对应gcc编译器的编译配置参数以参考。
glibc初始环境根据参考文章的作者描述,除开configure之外,该步骤属于临时性但又不得不做的措施。
tar xf glibc-2.23.tar.xz
mkdir build-glibc
cd build-glibc
../glibc-2.23/configure --prefix=/home/esper/gnu-aarch64/dist/aarch64-linux-gnu --build=x86_64-linux-gnu --host=aarch64-linux-gnu --target=aarch64-linux-gnu --with-headers=/home/esper/gnu-aarch64/dist/aarch64-linux-gnu/include --disable-multilib --disable-werror
make install-bootstrap-headers=yes install-headers
make -j4 csu/subdir_lib
install csu/crt1.o csu/crti.o csu/crtn.o /home/esper/gnu-aarch64/dist/aarch64-linux-gnu/lib
aarch64-linux-gnu-gcc -nostdlib -nostartfiles -shared -x c /dev/null -o /home/esper/gnu-aarch64/dist/aarch64-linux-gnu/lib/libc.so
touch /home/esper/gnu-aarch64/dist/aarch64-linux-gnu/include/gnu/stubs.h
cd ..其中根据参考文章的作者描述,glibc的configure必须显式指明build, host, target三个平台参数值。
这里的configure添加了--disable-werror参数,目的在于取消编译器将警告作为错误处理,进而终止编译过程的行为。该参数在软件的编写过程中十分有效,但是在编译一个已经公开发行且没有出现大问题的软件的时候,emm...还是关掉它吧
cd build-gcc
make -j4 all-target-libgcc
make install-target-libgcc
cd ..glibc此时才能使用目标平台的gcc编译glibc。
cd build-glibc
make -j4
make install
cd ..cd build-gcc
make -j4
make install
cd ..然后dist目录下就是一套完整的交叉编译工具链了。经过测试,该工具链已经可以生成能在目标平台运行的程序了,但在移动位置之后使用我还没试过。理论上是没问题的,因为arm官方发布的预编译包似乎就是这样。祝好运!
===========================================================
当场补充
相信看到这里,并且在机器上一步一步跟着做的读者(如果有的话)应该是长舒了一口气。然而,在下要在这里提一句,ubuntu上有预编译好的交叉编译工具链,如果你不知道的话。
sudo apt install gcc-5-aarch64-linux-gnu g++-5-aarch64-linux-gnu(逃
GCC GNU Compiler Collection GCC编译器套件
glibc GNU C LIBrary GNU的C运行库
两者是linux系统中使用最多的编译-运行套件。glibc可以视作独立的运行库,而GCC,甚至部分Linux操作系统组件都依赖于这套运行库。这就导致,glibc不能随意更新,因为版本变化,符号变化导致的运行库加载失败,很有可能会使系统直接崩溃(血的教训)。
所以在跨平台编译软件的时候,一定要使用目标平台格式的glibc库,不然链接不起来,或者会无法运行。
#include <stdio.h>
#ifdef __GLIBC__
#include <gnu/libc-version.h>
#endif
int
main(void)
{
#ifdef __GLIBC__
printf("GNU libc compile-time version: %u.%u\n", __GLIBC__, __GLIBC_MINOR__);
printf("GNU libc runtime version: %s\n", gnu_get_libc_version());
return 0;
#else
puts("Not the GNU C Library");
return 1;
#endif
}起因是收到一个任务:在PYNQ-Z2平台上搭建一个人脸识别系统。
当时第一时间就去了github,找到最热门的项目face_recognition,打算将其移植到arm平台上。然而在过程中遇到了数不胜数的坑。。其中之一就是依赖环境的配置。
dlib是一个提供机器学习和数据分析功能的C++库,也提供了python版本,使得可以通过python来调用其中的功能。然而,其提供方式简单粗暴,或许是为了能够达到每台机器的最佳性能,只提供了源码下载,自行编译安装的方法,甚至连Windows版的预编译包都没有提供(至少我没找到)。这就对于一些软件环境不全或者硬件配置不够的机器上安装该库的过程造成了一定的困难。(devs:反正我们的库是高级用途,那些辣鸡环境不配安装)
好在当前的硬件环境还是有通用型的,起码在同一平台下编译的软件可以在同一指令集架构Instruction Set Architecture, ISA下兼容运行,使得这些平台还是有运行dlib的可能。
本文即将提到的Pine A64+ 1GB SoC即属于上述的第二种情况:硬件配置不够。这里的不够指的并不是无法运行dlib。在编译过程中,目测到的最高内存占用达到2.1GB(amd64-aarch64交叉编译时),而默认配置的Pine A64内存1GB,内存交换空间swap 512MB,远远无法达到编译要求。实际上在Pine A64+上编译时,也可以观察到在内存不足时,会自动终止编译过程,并尝试从头开始。因而,在编译都无法完成的情况下,根本谈不上能不能运行。在对于交叉编译技术有了初步的了解后,决定使用amd64平台,配置更高的个人计算机进行交叉编译。
经过在Python包管理中心Python Package Index, PyPI的搜索后,发现一个名为crossenv的项目,根据描述,其目的在于为Python包交叉编译提供一个简化的配置过程,而这与我的目的恰好符合。过程记录如下。
toolchain到arm官网上可以找到下载地址(这里)。选择目标平台为aarch64-linux-gnu的工具链进行下载,使用时解压到linux文件系统中即可。
PATHexport PATH=/path/to/your/toolchain/bin记得PATH中添加的是可执行文件的路径,所以不要忘记加上bin子目录。
/path/to/your/toolchain是工具链根目录的位置,例如/home/esper/gcc-arm-8.3-2019.03-x86_64-aarch64-linux-gnu
Python库编译过程中会识别一些环境变量,比如CC, CFLAGS, C_INCLUDE_PATH一类的,C++对应的应该也是可用的。
export CC=aarch64-linux-gnu-gcc
export CXX=aarch64-linux-gnu-g++这些是按照crossenv推荐而进行的设置。CFLAGS就不用设置了,可能会覆盖原有的比如-O2一类的优化参数。
由于需要为目标平台编译软件,故需要使用目标平台的配置信息进行编译时的配置。 假设使用的存储卡被系统分配的标识符为/dev/sdb,挂载至用户的家目录下:
mkdir pine64
sudo mount /dev/sdb2 ~/pine64此时可通过~/pine64访问目标文件系统。
至于使用第二个分区的原因很简单,第一个是boot分区。
_sysconfigdata_m备份原有_sysconfigdata.py,将_sysconfigdata_m.py复制为_sysconfigdata.py。Python原本的设计方法是由_sysconfigdata.py通过当前程序的变量决定加载的系统信息文件,而crossenv会检查两者之间的信息兼容性,还会报错(不知道原理是啥,反正这里让人摸不着头脑)
cd ~/pine64/usr/include/python3.5/
sudo mv _sysconfigdata.py _sysconfigdata.py.bak
sudo mv _sysconfigdata_m.py _sysconfigdata.pycrossenv不认带有后缀的config文件夹,使用软链接解决
sudo ln -s config-3.5m-* config-3.5mcrossenvpip3 install crossenv
python3 -m crossenv ~/pine64/usr/bin/python3 vcenv使用以上命令安装crossenv,并根据目标平台的python可执行文件进行交叉编译环境的配置。
crossenv可以直接通过Python可执行文件进行调用,接收两个参数,其一为目标平台的Python可执行文件,其二为创建的虚拟环境的文件夹位置。以上命令将在当前目录生成一个名为vcenv的文件夹。
把对应架构下的pyconfig.h复制到gcc的include文件夹中
cp ~/pine64/usr/include/aarch64-linux-gnu/python3.5m/pyconfig.h /path/to/your/toolchain/aarch-linux-gnu/include/c++/8.3.0/aarch64-linux-gnu/python3.5m/pyconfig.h目标文件夹为工具链中aarch-linux-gnu/include/c++/8.3.0/aarch64-linux-gnu/python3.5m子目录。理论上来说,只有最后一层文件夹python3.5m是缺失的,需要手动创建。
strip v. 脱掉;脱去(衣服)
使用该命令可以脱除生成的文件中多余的符号信息,缩小目标文件的大小,为cmake自动调用。然而不知为何,cmake咬死了只认/usr/bin/strip,导致其无法正确读取编译生成的文件,进而报错,阻碍了下一步工作的进行。
莫得办法,好在由于交叉编译不需要宿主机的工具链,使用取巧的办法,暂时屏蔽原有的strip,换成交叉编译所需要的。
备份原有strip,把交叉工具链的软链接一下,因为cmake不认识环境变量定义的strip。
sudo mv /usr/bin/strip /usr/bin/strip-host
sudo ln -s /path/to/toolchain/bin/aarch64-linux-gnu-strip /usr/bin/strip完成编译后记得撤销操作
sudo rm /usr/bin/strip
sudo mv /ust/bin/strip-host /usr/bin/strippython setup.py buildpython setup.py bdist_egg轮子格式的参数为bdist_wheel
egg格式的可以使用easy_install命令直接安装。
whl格式的使用pip install命令安装。
不知为啥,我这里安装完以后又会自动重新开始下载编译dlib,取消就行了,再进Python发现已经可以import dlib了。
但是由于使用的工具链是gcc8,使用了glibc2.28的特性。而系统编译时只使用了2.23,故需要升级glibc方可测试所编译的dlib库是否可以正常运行。该过程将另起一篇文章叙述。
PYNQ-Z2的更麻烦,是32位系统。。。需要32位的python(咕咕)
=======================================================
后续补充
麻烦个吉尔,还简单些。采用的交叉工具链使用的glibc版本为2.28,而pine64所使用的glibc版本为2.23。然而这里兼容性恰好相反,pine64的系统只支持最高版本为2.23,而实际编译好的库需要使用2.27。glibc相当于系统的地基了,又不能轻易动。。。反倒是pynq还好,是近两年出来的,用的glibc库似乎恰好是2.27,编个32位的python,直接交叉编译,完成就能用。
也就是说,要在pine64上运行dlib的话,只有两个方法了:一个是拿更新的glibc(>=2.27)重新编译系统,另一个是编译一个更老的gcc(<=2.23)用于编译dlib。
=======================================================
我又回来了
可以利用虚拟内存完成编译
临时性地扩大总可用内存容量
dd if=/dev/zero of=/home/esper/tmp.swp bs=1024K count=1024
sudo chown root && sudo chgrp root && sudo chmod 600
sudo mkswap /home/esper/tmp/tmp.swp
sudo swapon /home/esper/tmp/tmp.swp关机/重启会卸载虚拟内存,如何持久性地增大虚拟内存百度即可。